
Meta unveils Llama 3 and claims it's the "most powerful" open source language model
Meta has introduced Llama 3 — a large-scale language model of the new generation, which it boldly calls "the most capable open-source LLM." The company has released two versions: Llama 3 8B and Llama 3 70B with 8 and 70 billion parameters respectively. According to the company, the new AI models significantly outperform previous-generation models and are among the best models for generative AI currently available.
In support of its claims, Meta cites the results of popular tests such as MMLU (knowledge), ARC (learning ability), and DROP (text fragment analysis). Llama 3 8B surpasses other open-source models in its class, such as Mistral 7B from Mistral and Gemma 7B from Google with 7 billion parameters, in at least nine tests: MMLU, ARC, DROP, GPQA (biology, physics, and chemistry questions), HumanEval (code generation test), GSM-8K (math problems), MATH (another math test), AGIEval (task-solving test), and BIG-Bench Hard (commonsense reasoning assessment).
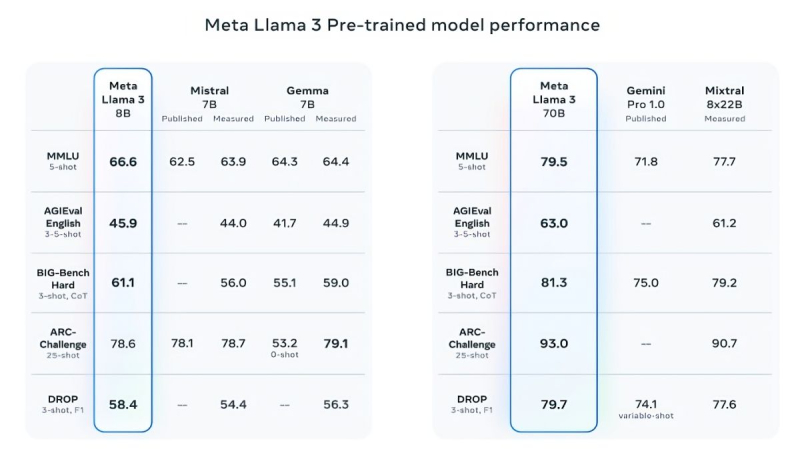
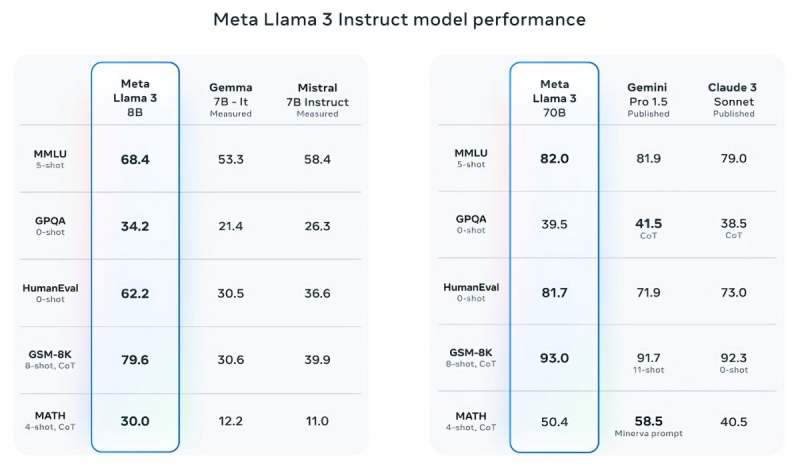
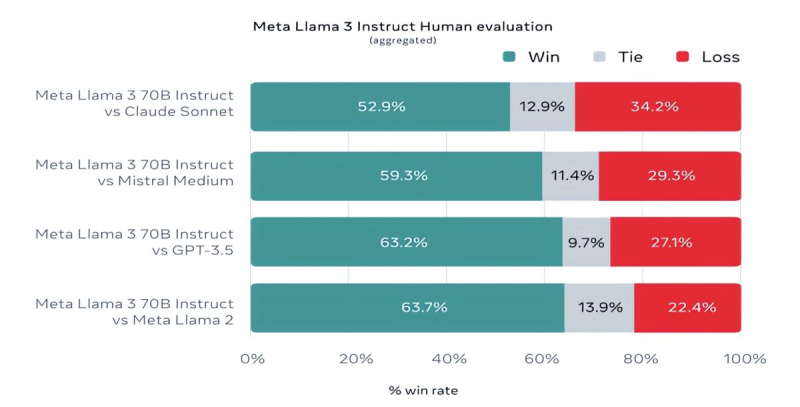
Mistral 7B and Gemma 7B are no longer considered state-of-the-art, and in some tests, Llama 3 8B does not show significant superiority over them. However, Meta is much prouder of the more advanced model, Llama 3 70B, which it places alongside other flagship models for generative AI, including Gemini 1.5 Pro — the most advanced in Google's Gemini lineup. Llama 3 70B outperforms Gemini 1.5 Pro in MMLU, HumanEval, and GSM-8K tests, but it lags behind the advanced model Claude 3 Opus from Anthropic, surpassing only the weakest model in the series, Sonnet, in five tests: MMLU, GPQA, HumanEval, GSM-8K, and MATH. Meta has also developed its own set of tests, from text and code writing to summaries and conclusions, in which Llama 3 70B outperforms Mistral Medium, GPT-3.5 from OpenAI, and Claude Sonnet from Anthropic.
According to Meta, the new models are more "controllable," less likely to refuse to answer questions, and generally provide more accurate information, including in some scientific areas, which is likely due to the vast amount of data used to train them: 15 trillion tokens and 750 billion words, seven times more than Llama 2.
Where did all this data come from? Meta assures that it is all taken from "publicly available sources." In the training data set for Llama 3, there was four times more code compared to that used for Llama 2, and 5% of the set consisted of data in 30 languages other than English to improve its performance with them. Additionally, synthetic data was used, obtained from other AI models.
"Our current AI models are tuned to respond only in English, but we train them using data in other languages to better recognize nuances and patterns," commented Meta.
The question of the necessary amount of data for further AI training has been raised particularly often lately, and Meta has already tarnished its reputation in this area. It was recently reported that Meta, in pursuit of competitors, was "feeding" AI with copyrighted e-books, although the company's lawyers warned of possible consequences.
Regarding security, Meta has embedded several security protocols into the new generation of its AI models, such as Llama Guard and CybersecEval, to combat the unauthorized use of AI. The company has also released a special tool called Code Shield for analyzing the security of open-source generative AI model code, allowing it to detect potential vulnerabilities. It is known that these protocols did not protect Llama 2 from unreliable answers and the disclosure of personal medical and financial information in the past.
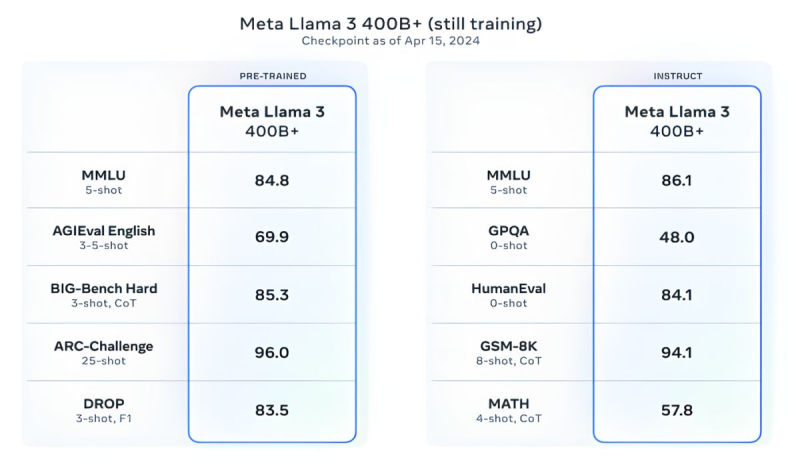
But that's not all. Meta is training the Llama 3 model with 400 billion parameters — it will be able to speak in different languages and accept more input data, including working with images. "We aim to make Llama 3 a multilingual and multimodal model capable of considering more context. We also strive to improve the performance and expand the capabilities of the language model in reasoning and code writing," said Meta.
- Related News
- OpenAI has introduced SearchGPT, an AI-powered search engine
- Musk claims humanoid robots will be used in Tesla in 2025
- Designer: Microsoft introduces new service for generating images
- OpenAI introduces GPT-4o Mini: What is it capable of?
- Synchron integrates ChatGPT with human brain
- Beta version of WhatsApp for Android already converts voice messages to text
- Most read
month
week
day
- Buyers massively complain about Samsung's Galaxy Buds 3 and Buds 3 Pro headphone, even finding hair in the box 824
- With today's mortgage interest rates, banks simply cannot sell products in 2025: Interview with Vardan Marutyan 816
- Ants and bees 'taught' tiny drones to navigate without GPS, beacons or lidars 677
- Samsung will release Galaxy Tab S10+ and Ultra tablets and Galaxy Z Fold 6 Slim and Galaxy w25 smartphones in October 645
- Mass production of iPhone SE 4 will begin this October, with sales starting in 2025 607
- Insider unveils specs of all smartphones of iPhone 17 series, including the 17 Slim 606
- Telegram's monthly active audience reaches 950 million 587
- What are the problems in the construction industry? Interview with Vardan Marutyan 567
- For the first time in history, iPhone will get a Samsung camera 564
- What dangers can feature phones from unknown manufacturers conceal? 560
- Archive