
Meta-ն ներկայացրել է Llama 3-ը և պնդում է, որ այն բաց կոդով «ամենահզոր» լեզվական մոդելն է
Meta-ն ներկայացրել է Llama 3-ը՝ հաջորդ սերնդի լեզվական մեծ մոդելը, որն ընկերությունն անվանում է այս պահին շուկայում առկա բաց կոդով ամենահզոր լեզվական մոդելը։ Ընկերությունը թողարկել է երկու տարբերակ՝ Llama 3 8B և Llama 3 70B, համապատասխանաբար, 8 և 70 միլիարդ պարամետրերով։ Meta-ի տվյալներով՝ արհեստական բանականության (ԱԲ) այս նոր մոդելները զգալիորեն գերազանցում են նախորդ սերնդի համապատասխան մոդելներին և ներկայումս առկա գեներատիվ ԱԲ-ի լավագույն մոդելներից են։
Իր պնդումն ապացուցելու համար Meta-ն մեջբերում է հանրահայտ MMLU (գիտելիք), ARC (սովորելու ունակություն) և DROP (տեքստային հատվածների վերլուծություն) թեստերի արդյունքները: Llama 3 8B-ը գերազանցում է իր դասի այլ բաց կոդով մոդելներին, ինչպիսիք են Mistral-ի Mistral 7B-ը և Google-ի Gemma 7B-ը՝ 7 միլիարդ պարամետրով, առնվազն ինը փորձարկումներում՝ MMLU, ARC, DROP, GPQA (կենսաբանություն, ֆիզիկա և քիմիա), HumanEval (կոդի գեներացում), GSM-8K (մաթեմատիկական խնդիրներ), MATH (մաթեմատիկական մեկ այլ թեստ), AGIEval (խնդիրներ լուծելու թեստերի հավաքածու) և BIG-Bench Hard (առողջ տրամաբանության հիման վրա դատողությունների գնահատման թեստ):
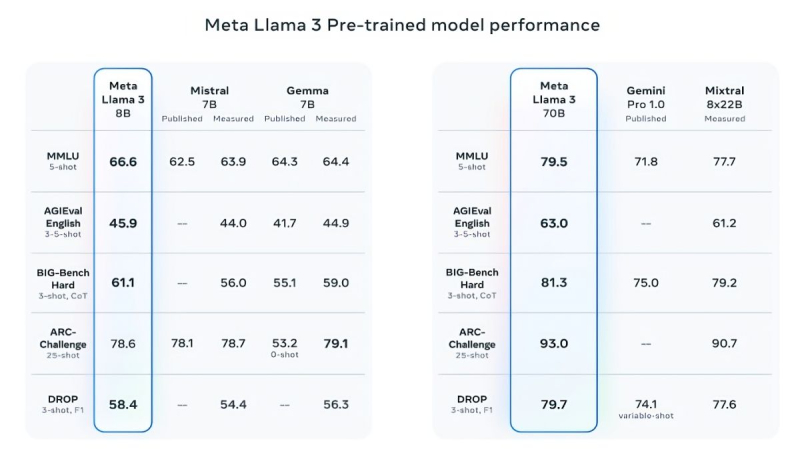
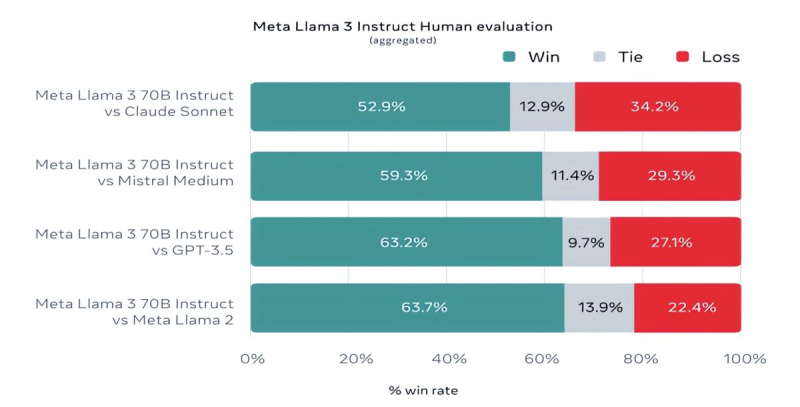
Mistral 7B-ն և Gemma 7B-ն արդեն դժվար է ժամանակակից անվանվել, մինչդեռ որոշ թեստերում Llama 3 8B-ն էական գերազանցություն չի ցուցաբերում դրանց նկատմամբ: Այնուամենայնիվ, Meta-ն շատ ավելի հպարտ է իր ավելի առաջադեմ մոդելով՝ Llama 3 70B-ով, որին դասում է գեներատիվ ԱԲ-ի այլ առաջատար մոդելների շարքին, ներառյալ Gemini 1.5 Pro-ի, որը Google-ի Gemini շարքի ամենաառաջադեմն է: Llama 3 70B-ը գերազանցում է Gemini 1.5 Pro-ին MMLU, HumanEval և GSM-8K թեստերում, սակայն զիջում է Anthropic-ի առաջատար Claude 3 Opus-ին, հինգ թեստերում (Sonnet-ին՝ MMLU, GPQA, HumanEval, GSM-8K և MATH) հաղթելով միայն շարքի ամենաթույլ մոդելին: Meta-ն նաև մշակել է թեստերի իր փաթեթը (տեքստեր գրելուց և կոդավորումից մինչև ամփոփում և եզրակացություն): Այս հարցում Llama 3 70B-ը հաղթել է Mistral Medium-ին, OpenAI-ի GPT-3.5-ին և Anthropic-ի Claude Sonnet-ին:
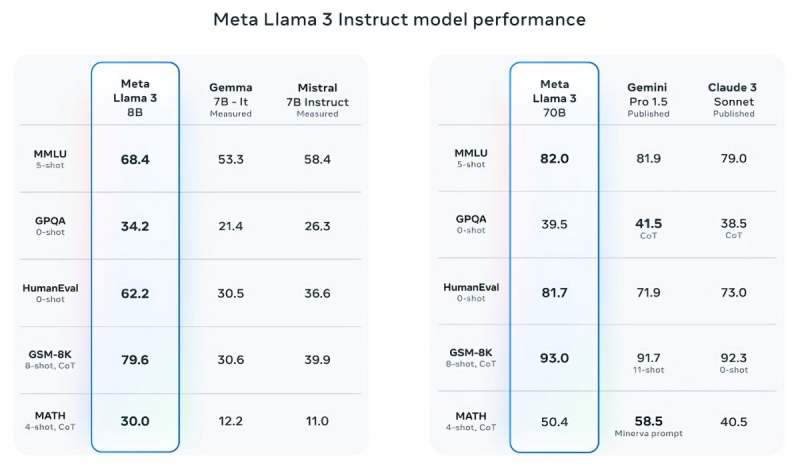
Ըստ Meta-ի` նոր մոդելներն ավելի կառավարելի են, ավելի քիչ հավանական է, որ հրաժարվեն հարցերին պատասխանելուց և, ընդհանուր առմամբ, ավելի ճշգրիտ տեղեկություն են գեներացնում, այդ թվում գիտական որոշ ոլորտներում, ինչը, հավանաբար, արդարացված է՝ հաշվի առնելով դրանց ուսուցանման համար օգտագործվող տվյալների հսկայական ծավալը՝ 15 տրիլիոն թոքեն և 750 միլիարդ բառ, ինչը յոթ անգամ ավելի է, քան Llama 2-ի դեպքում:
Իսկ որտեղի՞ց այս բոլոր տվյալները Meta-ին։ Ընկերությունը սահմանափակվել է՝ միայն վստահեցնելով, որ դրանք բոլորը վերցված են «հանրային հասանելի աղբյուրներից»: Այնուամենայնիվ, Llama 3 ուսուցման տվյալների հավաքածուն պարունակում էր չորս անգամ ավելի շատ կոդ, քան օգտագործվում էր Llama 2-ի համար, և հավաքածուի 5%-ը բաղկացած էր 30 ոչ անգլալեզու տվյալներից: Բացի դրանից՝ օգտագործվել են սինթետիկ տվյալներ, այսինքն՝ ստացված այլ ԱԲ մոդելներից։
«Մեր ներկայիս ԱԲ մոդելները կազմաձևված են միայն անգլերենով պատասխանելու համար, բայց մենք դրանք վարժեցնում ենք այլ լեզուներով տվյալների օգտագործմամբ, որպեսզի ԱԲ-ն կարողանա ավելի լավ ճանաչել նրբերանգներն ու օրինաչափությունները»,- մեկնաբանել է Meta-ն:
Վերջին շրջանում հատկապես հաճախ է արծարծվում արհեստական բանականության հետագա վերապատրաստման համար անհրաժեշտ քանակությամբ տվյալների հարցը, և Meta-ն արդեն հասցրել է փչացնել իր հեղինակությունն այս ոլորտում։ Վերջերս հաղորդվեց, որ մյուս ընկերությունների հետ մրցակցելու համար Meta-ն հեղինակային իրավունքով պաշտպանված էլեկտրոնային գրքերի ինֆորմացիան տրամադրում է ԱԲ-ին, թեև ընկերության իրավաբանները նախազգուշացրել են հնարավոր հետևանքների մասին:
Ինչ վերաբերում է անվտանգությանը, ապա Meta-ն անվտանգության մի քանի արձանագրություններ է ներդրել իր նոր սերնդի ԱԲ մոդելներում, ինչպիսիք են Llama Guard-ը և CybersecEval-ը՝ ԱԲ-ի չարաշահման դեմ պայքարելու համար: Ընկերությունը նաև թողարկել է Code Shield կոչվող հատուկ գործիք՝ վերլուծելու համար բաց գեներատիվ ԱԲ մոդելների կոդի անվտանգությունը, որը հնարավորություն է տալիս բացահայտել հնարավոր խոցելիությունները: Հայտնի է, որ նախկինում այս նույն արձանագրությունները չէին կանխում Llama 2-ի կողմից սխալ պատասխանների և անձնական բժշկական և ֆինանսական տեղեկությունների տրամադրումը։
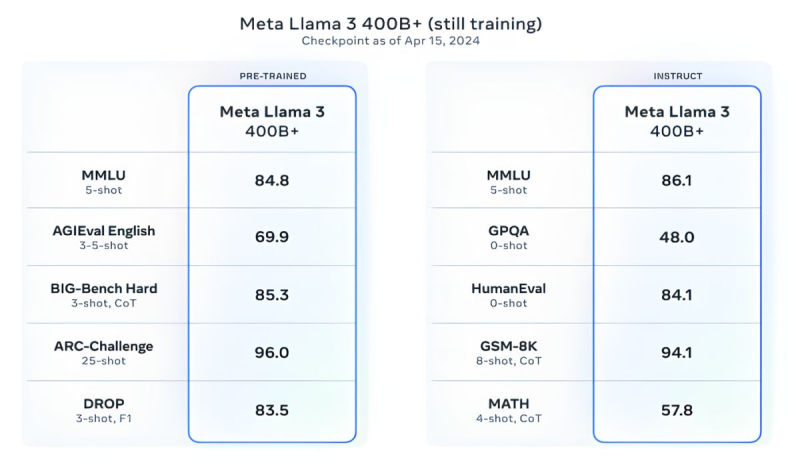
Սա դեռ ամենը չէ: Meta-ն ուսուցանում է Llama 3 մոդելը 400 միլիարդ պարամետրով. այն կկարողանա խոսել տարբեր լեզուներով և ընդունել ավելի շատ մուտքային տվյալներ, ներառյալ պատկերների հետ աշխատելը: «Մենք ձգտում ենք Llama 3-ը դարձնել բազմալեզու և բազմամոդալ մոդել, որը կարող է հաշվի առնել ավելի շատ համատեքստ: Մենք նաև փորձում ենք բարելավել նրա կատարողականը և ընդլայնել լեզվական մոդելի հնարավորությունները դատողությունների և կոդ գրելու հարցում»,- ասել է Մետան:
- Այս թեմայով
- Ութ խոշոր թերթեր OpenAI-ին և Microsoft-ին դատի են տվել ԱԲ զարգացման նպատակով իրենց բովանդակությունն ապօրինաբար օգտագործելու համար
- Ներկայացվել է ռոբոտ, որն ուտեստ է պատրաստում, մատուցում, գինի լցնում, արդուկ անում, ծալում արդուկած շորերը
- Google-ի Gemini ԱԲ-ն արդեն հասանելի է Android-ի հին տարբերակների համար
- Google-ն աշխատանքից ազատել է 28 աշխատակցի, որոնք բողոքել են Իսրայելի հետ ընկերության համագործակցության դեմ
- WhatsApp-ում արհեստական բանականության գործառույթ կներդրվի․ ի՞նչ է այն անելու
- Dօing Digital 2024 համաժողովի գործընկերներ Fastex-ը, Ucraft-ը և Hoory-ն հատուկ մրցանակների են արժանացել
- Ամենաընթերցվածը
ամիս
շաբաթ
օր
- Ապոկալիպսիս. ե՞րբ և ինչպե՞ս կկործանվի Երկիր մոլորակը (վիդեո) 4196
- Ինսայդերը ցուցադրել է iPhone 16-ի բոլոր 4 մոդելների մակետները՝ առջևից և հետևից 2799
- Ակնկալիք vs իրականություն. ինչպես է իրականում աշխատում փորձնակությունը միջազգային ընկերությունում 2628
- Ի՞նչ կլինի Երկրի հետ, եթե Լուսինն անհետանա 2361
- iPhone 16-ի հետևի վահանակը կարող է 7 գույնի փայլատ ապակի ստանալ 2335
- Զահա Հադիդի ճարտարապետական 10 ամենահետաքրքիր աշխատանքները 1982
- ՏՏ ոլորտի խոշոր հարկատուները․ ի՞նչ փոփոխություններ են գրանցվել 2024-ի 1-ին եռամսյակում 1671
- ՌԴ-ում սմարթֆոնը բռնկվել է անմիջապես երեխայի ձեռքում 1588
- Ներկայացվել է բացառիկ Redmi Note 13 Pro+ սմարթֆոն՝ նվիրված Մեսսիին և Արգենտինայի հավաքականին 1545
- Instagram-ը փոխում է մոտեցումը. ինչպե՞ս այն կօգնի առաջխաղացնել բնօրինակ բովանդակությունը և պայքարել վերահրապարակողների դեմ 1475
- Արխիվ